LFM2.5について
みなさんは「LFM2.5」をご存知だろうか。これはAIモデルで、特に1.2Bという極めて軽量なモデルである。
公式サイト
https://www.liquid.ai/blog/introducing-lfm2-5-the-next-generation-of-on-device-ai
1.2Bがどのぐらい軽いかというと、現代のコンピュータであればノートPCでも問題なく動作でき、スマートフォンなどでも動作するレベルの軽量性である。
なおこのLFM2.5が公開されたのは1月5日であり、最先端の軽量AIモデルである。
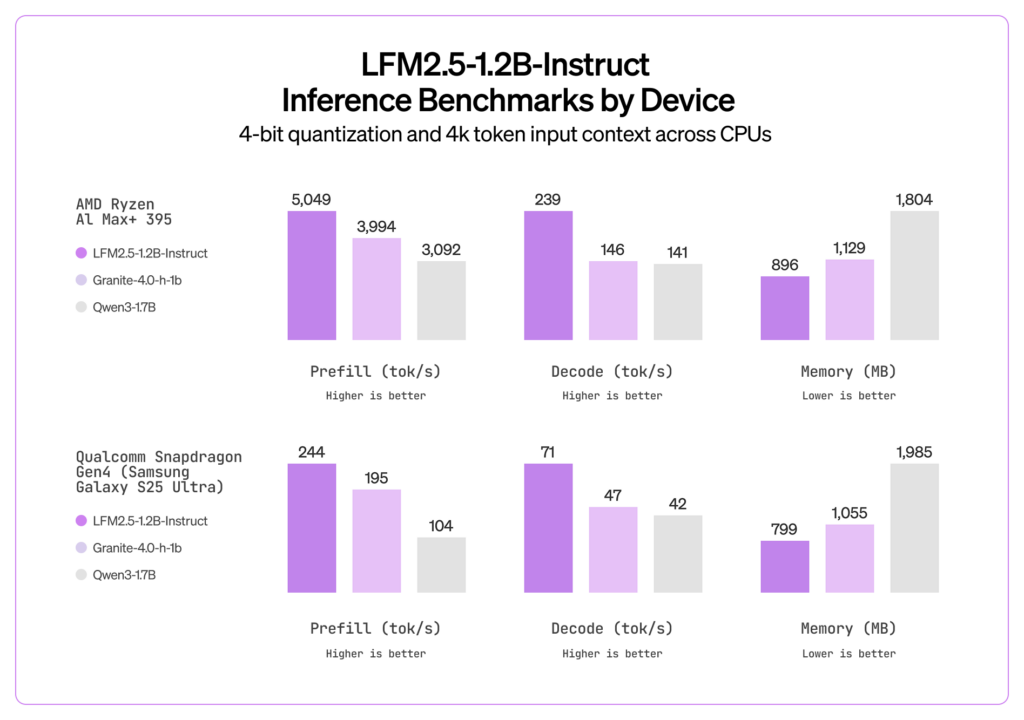
上の画像はAMDのRyzenとSamsungのGalaxy S25 Ultraで他のAIモデルと比較したグラフである。
ここでの単位は「トークン毎秒」で数値が高い方が出力が速いということだ。その他のAIモデルと比べて速いのがわかるだろう。
また、あくまで体感だがGPT3.5と比べても同じ精度で出力することができている。むしろこっちの方がやや正確かもしれない。

この画像は完全にローカル環境で実行した画像だ。写っているのは一部分でもう少し長く出力された。
生成終了までかかった時間は40秒ほど。実行環境はiMac late 2015(i5 5250U,8GB,オンボードGPU)だ。10年前の事務用PCである。しかも後ろで通話とネットサーフィンをしながら実行している。
いかにこのモデルが軽量であるかわかると思う。
インストール方法
さて、インストール方法を解説しよう。ただ、軽量のAIモデルとは言っても最低限の性能は必要だ。とはいえ、相当前のPCでなければ問題ないだろうと思う。Windows11が入っているようなPCであれば問題ないだろう。
まずは、LLMフレームワークが必要だ。筆者はOllamaを使っているのでその方法で進めよう。
まずOllama公式サイトにアクセスし、自身の使用しているOSに合わせてダウンロードする。
現在はWindowsでもGUIで使えるようだ。(古いバージョンではCUIのみだった)
インストールが終わったらWindowsならコマンドプロンプト、Macならターミナルを起動する。コンソールウィンドウを開いたら
ollama run hf.co/LiquidAI/LFM2.5-1.2B-Instruct-GGUF:Q4_K_Mと入れよう
なおこれはOllamaを使う場合でその他のフレームワークを使う場合は
https://huggingface.co/LiquidAI/LFM2.5-1.2B-Instruct-GGUFへアクセスして「Use this model」を選択、各フレームワークの指示に従ってほしい。
その後使用するモデルをLLM2.5に設定、「こんにちは」と入れてみよう。
どうだろうか。うまく動いただろうか。
PCによっては読むのが追いつかないほどの速度で生成されるだろう。ぜひいろいろと試してみてほしい。
なお余談だが、このLFM2.5は日本語特化モデルや視覚言語モデル、音声言語モデルもある。今回紹介したのは汎用モデルのinstructだがこれらのモデルも試してみると面白いかもしれない。
ということで今回は軽量AIモデル、「LLM2.5」を紹介した。
ではまた今度。