先日NVIDIAの開発する「DLSS」の最新バージョンが発表された。

さて、この手の話題に詳しい方ならもうすでに分かっていると思うが、絶賛炎上中だ。
具体的にはゲームに「AIフィルター」をかけるのはコンテンツクリエイターや、CGクリエイターに対する冒涜であるというものだ。
これに対してNVIDIAのCEOは「コンテンツクリエイターが自由にコントロールできるものである」として反論した。
まあここまでの流れは皆さんも理解していると思うが、私としてはこれまでの批判に加え、別の観点からこの技術を批判したい。
それは
明確なビジュアルの変更を含む技術を自社GPUのみで使用するのは表現の幅を狭め、ゲーム産業を破壊する
ということだ。
まず、DLSSはNVIDIAのGPUでしか使えない。そのうえで、「レンダリング」という極めてビジュアルに大きく関係する箇所にこの技術を使用するのは今後のゲーム開発に重大な影響を及ぼしかねないと思う。
DLSSが出てからどうだろうか。AIによるフレーム生成により最終的なFPSは増加した。しかし実際には半分のFPSしか出ておらず、DLSSに頼り最適化を怠るのではないかという懸念がある。
実際に特定のゲーム(名指しするならモンハンワイルズ)で最適化が圧倒的不足している事象があるだろう。
さらに、RadeonやIntel Arcでこれらの機能が使えないことも大きな問題点だ。
Steamハードウェア&ソフトウェア 調査によれば、現時点でのNvidiaGPUの使用率は73%であった。(今月は84%であったが中国の春節の影響が多くみられるため先月の割合を参考とする。毎年この時期はNvidiaGPUのシェアが高くなるとともに中国語のユーザーが以上に高くなる)
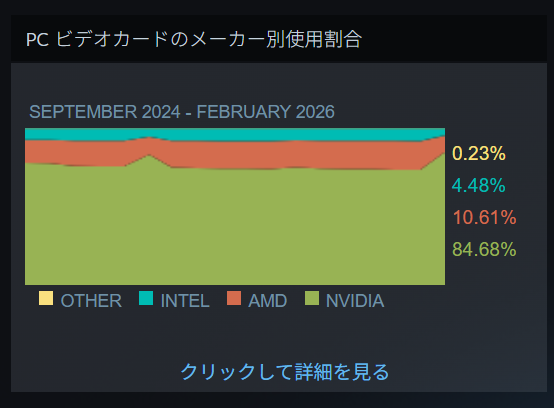
この技術は27%のゲームユーザーに対し劣化したグラフィックを提供することを意味する。
フレーム生成に至ってはFSRで実装できたものの、このようなゲームの中核に自社技術のAIを用いるのはNVIDIA以外のGPUを使っているユーザーをないがしろにしている。
実際にはこの技術を使うかどうかは自由である。しかしDLSSがもたらした最適化不足を見たものとして「これ前提」で作るのはゲーム制作の技術を後退させるだけでなく、市場の公平性からみても危険であると言わざるを得ない。
さて、とどのつまり
クリエイターがこの機能を積極的に使用するのは危険である
ということだ。「革新的なグラフィックを提供できるよ(NVIDIA専用でね!)」なんて言っているNIVIDAには強い懸念と疑念を抱かざるを得ない。
これで本当に革新的だと思っているのなら自惚れも大概にしてほしいものである
実際この機能の行きつく先はどうなるのだろうか。今後の動きも注視したい。
さて、今日はこのへんで。












{kind=link}
{kind=link}
{kind=link}